Psychology of Code Readability
By no means should this be regarded as truth, but rather a model that I’ve found extremely helpful in understanding and finding better ways of writing code.
I think one of the things every programmer strives for is writing better code. Readability is one of the aspects of “good code”. There have been many papers and books written on the topic, however I find many of them lacking. Not because of the recommendations, but rather the analysis part.
What makes some piece of code more readable than another? It’s one thing to say that it uses better variable names, but what makes a certain variable name easier to read? I really mean digging deeper into human psyche. It is our brain that is doing all the processing after all.
Psychology Primer #
As any programmer knows we have limited capacity to think about things. This is our working memory limit. There’s an old myth going around that we can hold 7±2 objects in our head. It is known as “The Magical Number Seven” and it isn’t entirely accurate. This number has been refined to 4±1 and some even suggest there isn’t a limit, but rather a degradation of ideas over time. For all intents and purposes we can assume that we have a small number of ideas we can process in our head at a given time. The exact number isn’t that important.
But some would still confidently say that they can handle problems involving more than 4 ideas. Luckily there’s another process going on in our brain called chunking. Our brain automatically groups information pieces into larger pieces (chunks).
Dates and phone-numbers are good examples of this:
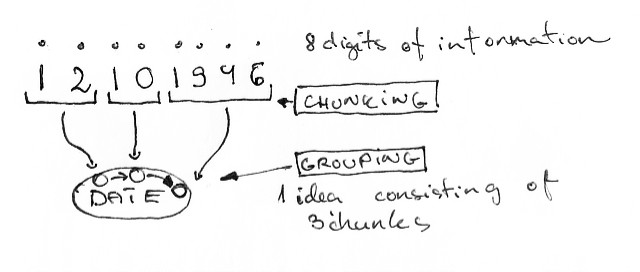
Two levels of chunking a date.
From these chunks we build up our long term memory. I like to imagine it as a large web of consisting many chunks, chunk sequences and groupings.

Memory Web
You might guess from this image that moving from one place to another in memory is slow. And you would be right. In UX there’s a concept called singular focus of attention. Which means that we can focus at a single thing at a time. It also has a friend called locus of attention, which says that our attention is also localized in space.
You might think this is the same thing as working memory limit, however there is a slight difference. Working memory capacity talks how big our focusing area is, the focus/locus of attention say that we can only do that when there is a place in our brain that contains the ideas.

Focus of Attention and Working Memory Capacity
The focus and locus of attention are important to know, because switching cost is significant. It is even slower when we need to create new chunks and groupings. It also goes the other way, the more familiar something is the less time it takes to make it our focus.
We also remember things better when we are in a similar context. This is called encoding specificity principle. This means by designing our encoding and recalling conditions we can design better what we remember.
In an experiment divers were assigned to memorize words on land and under water. Then recall them on land or in water. The best results were for people who memorized and recalled on land. Surprisingly the second best were the people that memorized and recalled on water. This showed that the context where you learn things has an impact on how well you can remember things.

Encoding Specificity Principle
To make things shorter, I’ll use context to refer to “focus and locus of attention” and how it relates to other chunks and loci. Effectively our brain is moving from one context to another. When we move our focus of attention we also remember what our previous contexts were, until our memory fades.
Related Contexts
From these contexts and chunks we build up mental representations and a mental model. There’s a slight difference between these two things. Mental representation is our internal cognitive symbol for representing the external world or a mental processes. Mental model can be thought of as a explanation of a mental representation. Often these terms are used interchangeably.
Mental models have a vital importance in our ability to precisely describe a solution to a problem. There are many different mental models possible for a single problem each having their own benefits and problems.
All of these ideas sound nice and precise, however our brains are quite imprecise. There are many other problems with our brain.
Our brains need to do more work when dealing with abstractions.
When ideas are similar their chunks are related and linked in our brains in a similar way. This leads to our brain being unable to “rebuild the contexts properly” because we are uncertain which chunk is the right one. Example: I and 1; O and 0.
Ambiguity is another source for uncertainty. When a thing is ambiguous then there are multiple interpretations for the same thing. Homonyms are the best example of this property. Example: Crane – the bird or the machine.
Uncertainty causes us to slow down. It might be a few milliseconds, but that can be enough to disrupt our state of flow or make us use more working memory than necessary.
There are of course interruptions that can disrupt our working memory, but there are also “smaller interruptions” called noise. If someone is saying random numbers and you are trying to calculate, then we can end-up accidentally start processing them and use up some of our working memory. This can happen also visually on screen when there are many irrelevant things between the important things.
Our brains also have trouble processing negation, with support from many studies. The effect of negation depends on the context, but negation should be used with care.
All of these together add up to cognitive load. It is the total amount of mental effort being used. Our processing capacity decreases with prolonged cognitive load and it is restored with rest. With prolonged cognitive load our minds also start to wander.
If this is new information to you, then I highly suggest taking a break now. These form fundamental properties that code analysis will rest upon.
I’m going to use the term programming artifact. By that I mean everything that is created as a result of programming. It might be a method you write, type declarations for a function, variable names, comments, Unreal Engine Blueprints, UML diagrams etc. Effectively anything that is a direct result of programming.
Here are a few recommendations, rules-of-thumb and paradigms analyzed in the context of psychology. By no means is this an exhaustive list or even a guide on what exactly to do. Probably there are many places where the analysis could be better, but this is more about showing how we can gain deeper insight into code readability by using psychology.
Scope of a name #
Length is not a virtue in a name; clarity of expression is. – Rob Pike
Let’s take a simple for loop:
|
|
Most programmers would recommend A. Why?
B. uses longer names which prevents us from recognizing this as a single chunk. The longer name also doesn’t help creating a better context, effectively it is just noise.
However, let’s imagine different ways of writing packages / units / modules / namespaces:
|
|
In example B. the namespace s is too short and doesn’t help “to find the right chunk”.
In example C. the namespace std.utils.strings is too long, most of it’s unnecessary, because strings itself is descriptive enough. (Unless you need to use multiple of them).
In example D. without namespaces, then the call becomes ambiguous, you might be unsure where the IndexOf comes from and what it is related to.
It’s important to mention that, if all of code is dealing with strings it will be quite easy to assume that IndexOf is some string related function. In such cases, even the strings part might be too noisy. For example: int16.Add(a, b) compared to a + b, would be much harder to read.
State of a variable #
With variables it would be easy to conclude that “modification is bad, because it makes harder to track what is happening”. But, lets take these examples:
|
|
Here foo is probably easiest to understand. Why? The problem isn’t modifying the variables, but rather how they are modified. A doesn’t have any complex interactions, which both B and C do. I would also guess, that even though C doesn’t have modifications, our brain still processes it as such.
|
|
Here is another example where the modification based version (D) is easier to follow. E introduces new variables for the same idea, effectively, the different variables become noise.
Idioms #
Let’s take another for loop:
|
|
How long did it take for you to figure out what each line is doing? For anyone who has been coding for a while, A probably took the least time. Why is that?
The main reason is familiarity. To be more precise, we have a chunk in our long-term-memory for A, however not for any of the others. This means that we need to do more processing, before we can extract the meaning and concept from it.
For any complete beginner, all of these would be processed quite similarly. They wouldn’t notice that one is “better” than any other.
A proficient programmers reads A as a single chunk or idea “i is looped for N items”. However a beginner reads this as “We initialize i to zero. Then we test whether each time we are still smaller than N. Then we add one to i.”
A is what you call the “idiomatic way” of writing the for loop. It’s not really better in terms of intrinsic complexity. However, most programmers can read it more easily, because it is part of our common vocabulary.
Most languages have an idiomatic way of writing things. There are even papers and books about them, starting with APL idioms, C++ idioms and more structural idioms like in GoF Design Patterns. These books can be regarded as a vocabulary for writing sentences and paragraphs, such that it will be recognized by people.
There’s however a downside to all of this. The more idioms there are, the bigger vocabulary you have to have to understand something. Languages with unlimited flexibility often suffer due to this. People end up creating “idioms” that help them write more concise code, however everybody else will be slowed down by them.
Consistency #
With regards to repeated structures names such as “model” and “controller” act as a chunk to remind of how these structures relate to each other.
Frameworks, micro-architectures and game engines all try to create and enforce such relations. This means people have to spend less time figuring out how things communicate and are wired up. Once you grok the structures it becomes easier to jump from one code base to another.
However the main factor with all of this is consistency. The more consistent the code base is in naming, formatting, structure, interaction etc. the easier it is to jump into arbitrary code and understand it.
Uncertainty #
As previously mentioned uncertainty can cause stuttering when reading or writing code.
Let’s take ambiguity as our first example. The simplest example would be [1,2,3].filter(v => v >= 2). The question is, what will this print, is it “2 and 3” or “1”. It’s a simple question, but it can cause a reading/writing stutter when you don’t use it day-in-out.
The source of the stutter is ambiguity. In the real-world there are two uses for it, one is to keep the part that is getting stuck in the filter and the other that passes through the filter. For example when you have gold in water, then you want to get rid of the water. When you have dirt in the water, you probably want to get rid of the dirt.
Even if we precisely define what filter does, it can still cause stutter because it’s hardwired with two meanings in our brain. The common solution is to use functions such as select, discard, keep.
We can also attach meaning in different ways, such as types. For example: instead of GetUser(string) you can use type CustomerID string to ensure GetUser(CustomerID) to make clear that the interpretation is “get user using a customer id” instead of other possibilities such as “get user by name”.
Similarity is also easy to conceptually understand. For example having variables such as total1, total2, total3 can lead to situation where you make copy paste mistakes or over a longer piece of code lose track what it meant. For example name such as sum, sum_of_squares, total_error can provide more meaning.
Having multiple names for the same thing can also be source of confusion when moving between packages. For example in one package you use variable name c, cl and in another client in the third source. It’s interesting to think about special variables such as this and self.
Ambiguity and similarity is not a problem just at the source level. Eric Evans noted this in DDD with the Ubiquitous Language pattern. The notion is that in different contexts such as billing and shipping, words such as “client” can have widely different usages and meanings, so it’s helpful to keep a vocabulary around to ensure that everyone communicates clearly.
Comments #
We have all seen the “stupid beginner examples” of commenting:
|
|
While it may look stupid, it might have some purpose. Think about learning a second or third language. You usually learn the new language by understanding the translation in your primary language. These are the “chunks” written out explicitly.
Once you have learned “chunk” the comments become noise, because you already know that information by looking at the second line.
As programmers get better, the intent of comments becomes to condense information and to provide a context for understanding code. Why was a particular approach taken when doing X or what needs to be considered when modifying the code.
Effectively, it’s for setting up the right mental model for reading the code.
Contexts #
Working memory limitation leads us to decompose and partition our code into different interacting pieces. We must be mindful in how we relate different pieces and how they interact.
For example when we have a very deep inheritance chain and we use things from all different inheritance levels, the class might be too complicated, even if each class has maybe two methods and each method is five lines of code. The class and all the parents form a single “whole”. Illustratively you can count each “inheritance step” as a “single idea” that you need to remember when you use that particular class.
The other side of contexts is moving between function calls. Each call is a “context in our mental model”, so we need to remember where we came from and how it relates to the current situation. The deeper the call stack, the more stuff we have to keep in mind.
One way to reduce the depth of our mental model contexts is to clearly separate them. One of such examples is early return:
|
|
In the first version when we read the “Do Something” part we understand it only happens when the age is positive. However, when we reach the “else” part we have forgotten what the condition was, because at that point the distance from the condition can be quite far away.
The second version is somewhat nicer. We have lost the necessity to keep multiple “contexts” in our head, but can focus instead of a single context that is setup and verified by multiple checks in the beginning.
Rules of thumb #
One of the usual recommendations is “don’t have global variables”. But, when a variable is set during startup and never changed again, is that a problem? The problem isn’t in the “variableness” or “globalness” of something, but rather in how it affects our capability to understand code. When something is modified at a distance then we cannot build a contained model of it. The “globalness” of course clutters the namespace (depending on the language) and means there are more places it can be accessed from. Of course there are many other things that have same properties, such as “Singleton”. So, why is it considered better than a global variable?
Single responsibility principle (SRP) is easy to understand with these concepts. It tries to ensure that we have proper chunks for a thing. This constraint often makes chunks smaller. Having a single responsibility also means that we end up with things that have working memory need. However, we need to consider that when we separate a class or function into multiple pieces we introduce many new artifacts. When these artifacts are deeply bound together we may not even gain the benefits of SRP.
Carmack’s comments on inlined functions is a good example of this. The three examples he gave were these:
|
|
By making pieces smaller we made the chunks smaller, however understanding the system became harder. We cannot read our code from top-to-bottom and understand what it does, but instead we have to jump around in the code base to read it. Version C preserves the linear ordering while still maintaining the conceptual chunks.
Summary #
Overall we can summarize the code readability as trying to balance different aspects:
- Names help us retrieve the right chunks from memory and help us figure out their meaning. Too long a name can end up being noisy in our code. Too short a name may not help us figure out its true meaning. Bad names are misleading and confusing.
- To minimize the cost of shifting attention, we try to write all related code close together. To minimize the burden to our working memory, we try to split the code into smaller and more fathomable units.
- Using common vocabulary allows the author as well as the team to rely on previous code-reading experience. That means reading, understanding and contributing to code is easier. Using unique solutions in place where a common one would do, can slow down new readers of that code.

In practice there is no “perfect” way of organizing code, but there are many trade-offs. While I focused on readability, it is never the end goal, there are many other things to consider like reliability, maintainability, performance, speed of prototyping.
See the next part Learning Code Readability for suggestions on how to improve your skills. And thoughts on What is a Layer.